")
Semua insinyur (engineer) tau bahwa manajemen kebutuhan (requirement management) adalah sesuatu yang kritikal dalam kesuksesan suatu proyek.
Requirement yang jelek akan membuat delivery proyek menjadi telat, menghabiskan uang lebih banyak dan menjadikan kualitas produk yang jelek pula.
Lalu bagaimana agar tim engineering dapat menghindari requirement yang jelek, tidak lengkap dan ambigu?
Sebelumnya mari kita lakukan penyegaran ingatan tentang SDLC / Software Development Life Cycle dan requirement engineering.
Secara singkat SDLC memiliki 4 tahapan yang bisa disebut PADI, saya ambil singkatan ini dari kuliahnya Pak Romi Satria Wahono yang kepanjanganya adalah planning, analysis, design dan implementation.
Setiap perangkat lunak yang akan dibangun akan melalui tahap-tahap tersebut dan Requirement engineering berperan sangat penting pada tahap analisis. Dalam proses requirement engineering, requirement akan ditranslate dari yang tidak jelas menjadi jelas, dari yang tidak lengkap menjadi lengkap dan tepat. Hasil kerja dari proses tersebut adalah sebuah dokumen yang akan dijadikan kontrak kerja atau acuan antara stakeholder / pengguna dengan software developer / pengembang perangkat lunak.
Kembali ke pertanyaan sebelumnya, bagaimana agar tim engineering dapat menghindari requirement yang jelek, tidak lengkap dan ambigu? Tentu saja dengan menjalankan proses SDLC yang sesuai dan juga proses requirement engineering yang tepat.
Bagaimana cara melakukanya dengan lebih cepat dan tepat? apakah manusia dapat dengan konsisten melakukannya?
Umumnya tidak bisa, karena manusia adalah mahluk sosial dan emosional. Disinilah peran disiplin ilmu kecerdasan buatan dan linguistic, untuk membantu manusia bekerja lebih optimal. Dengan memanfaatkan NLP / Natural Language Processing, proses analisa requirement dapat menjadi lebih cepat dan bahkan bisa di otomatisasi.
Apa keuntungan menggunakan AI untuk manajemen requirement engineering?
- Mengurangi kesalahan
- Fase analisa requirements bisa saja memakan waktu 2 persen dari total waktu desain, tapi requirements yang jelek akan berkontribusi lebih dari 50 persen atas kesalahan dalam proses pengembangan perangkat lunak
- Mengurangi biaya
- Biaya yang dikeluarkan untuk memperbaiki kesalahan akan meningkat secara eksponensial seiring berjalannya proyek. Dengan memanfaatkan AI diharapkan dapat mengurangi biaya pengembangan dan keterlambatan dengan mendeteksi cacat (defect) pada tahap awal analisa requirements sehingga dapat menghemat biaya dikemudian hari
- Meningkatkan kualitas requirement
- Mengisolasi isu yang terdapat pada requirements sebelum di review secara manual oleh manusia. Dan juga sistem dapat memberikan saran untuk melakukan peningkatan kualitas requirements
Sebuah studi dari Pulitzer Prize-winning IT consultant dan penulis James Martin menemukan bahwa:
- Sebanyak 56 persen penyebab utama semua cacat yang teridentifikasi pada proyek perangkat lunak ditemukan pada saat analisis requirement dan fase pendefinisian requirement.
- Sekitar 50 persen dari cacat requirements yang terjadi adalah karena cara menulis requirement yang asal jadi, tidak jelas, ambigu atau salah pemahaman.
- 50 persen lainnya adalah dikarenakan tidak lengkapnya spesifikasi atau ada syarat-syarat yang dihilangkan atau tidak tercatat.
- 82 persen pekerjaan ulang aplikasi berkaitan dengan kesalahan pada requirements.
Ok saya pikir cukup tentang penjelasanya, sekarang saya akan tunjukan konsep aplikasi dari AI dan NLP dalam proses requirement engineering yang menggunakan analisis berbasis object atau object-oriented analysis and design. Gambar-gambar yang akan saya pakai adalah gambar ilustrasi yang diambil dari website visual-paradigm.com (Disclaimer: saya tidak berafiliasi dengan produk tersebut).

Proses analisis tekstual biasanya dimulai dari deskripsi masalah, cerita pengguna atau konsumen, informasi tersebut bisa didapat dalam bentuk teks atau audio. Dalam proses analisis tekstual secara manual seorang IT Business Analyst akan melakukan identifikasi untuk mendapatkan informasi tentang aktor dan use case yang ada dalam suatu deskripsi masalah. Dan bahkan juga dapat mengembangkan deskripsi masalahnya, menghubungkan keterkaitan satu masalah dengan yang lainnya.
Teks dan file audio adalah unstructured data atau data yang tidak terstruktur lain halnya dengan data terstruktur yang sudah dalam bentuk baris dan kolom atau data semi-structured seperti file dengan isi format JSON.
Untuk mengolah data teks yang tidak terstruktur salah satu teknologi yang sudah umum digunakan adalah NLP. Dengan menggunakan NLP data yang tadinya tidak terstruktur akan diolah menjadi data terstruktur. Kemudian digabung dengan disiplin ilmu machine learning untuk melakukan klasifikasi entitas.
Dari ilustrasi gambar diatas dapat dilihat input dan outputnya:
- Input: deskripsi masalah dalam bentuk tekstual
- Output: klasifikasi entitas, seperti actor, use case, dan ada juga klasifikasi lainnya yaitu class, term, action, activity, dan requirement / business rule
Setelah melakukan klasifikasi tersebut, maka sistem dapat menghasilkan Use-Case diagram. Seperti ilustrasi berikut:
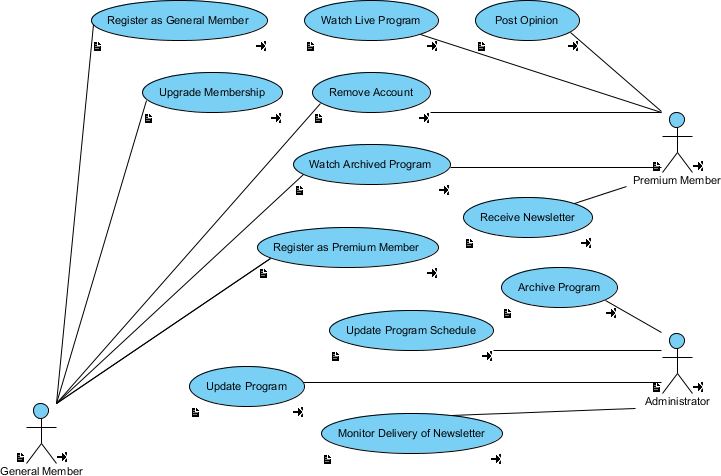
Dan tidak hanya sampai disitu, bahkan bisa juga menghasilkan class diagram dan conceptual Entity-Relationship Diagram dan juga bisa menghasilkan baseline source code. Lah! trus programmer kerjanya apa? tentunya programmer akan lebih cepat kerjanya karena sudah ada basis kode yang menjadi acuannya. Profesi programmer akan terus ada, hanya saja skill-set programming language nya yang nanti berevolusi.
Dengan melihat hal tersebut, seharusnya kamu sudah bisa melihat potensinya ya 🙂
Tapi jangan anggap remeh ya, untuk membuat sistem atau aplikasi seperti itu tidaklah mudah, perlu melakukan riset terlebih dahulu, kamu bisa browsing di Google tentang berbagai macam riset terkait NLP dan Requirement Engineering.
Lalu pengetahuan apa yang kamu perlukan untuk membangun perkakas (tool) semacam itu? yaitu pengetahuan dalam hal business domain knowledge, requirement engineering, software engineering / software development, data engineering dan tentunya artificial intelligence, machine learning dan natural language processing.
Yang utama adalah kamu harus memiliki business domain knowledge minimal pada satu bidang bisnis, karena untuk membuat model dan melatih machine learning diperkukan dataset yang spesifik untuk masing-masing bidang bisnis. Setiap bidang bisnis biasanya memiliki istilah-istilah khusus, seperti halnya di bidang kesehatan dengan pertanian, masing-masing memiliki istilah-istilah atau jargon yang spesifik dan sistem yang kamu buat harus memahami istilah-istilah tersebut.
Ada baiknya melakukan penelitian secara berkelompok untuk hasil yang lebih baik, agar masing-masing subjek pengetahuan bisa di pahami lebih dalam melalui kolaborasi.
Semoga artikel singkat ini bisa bermanfaat untuk pembacanya 🙂
Baca lebih lanjut:
- The Role of Requirement Engineering in Software Development Life Cycle
- Engineering breakthrough: IBM introduces Watson AI for RQA
- Requirements Quality Assistant Brings Watson AI to Requirements Management
- Making the Analysis of Requirements Documents Easier
- Leveraging Natural Language Processing In Requirements Analysis: How to Eliminate Over Half of All Design Errors Before they Occur by QRA Corp
- Change Impact Analysis for Natural Language Requirements: An NLP Approach
- NARCIA: An Automated Tool for Change Impact Analysis in Natural Language Requirements
- Natural Language Processing For Requirements Engineering
- The Applications of Natural Language Processing (NLP) for Software Requirement Engineering – A Systematic Literature Review
- Natural Language Processing for Information and Project Management
- Requirement Analysis using Natural Language Processing
- An NLP Based Requirements Analysis tool
- Natural Language Processing: Mature Enough for Requirements Documents Analysis?
- The Role of Natural Language Processing in Requirement Engineering
- Computational Science and Its Applications – ICCSA 2019: 19th International
- Natural Language Processing for Requirements Engineering: The Best Is Yet to Come





